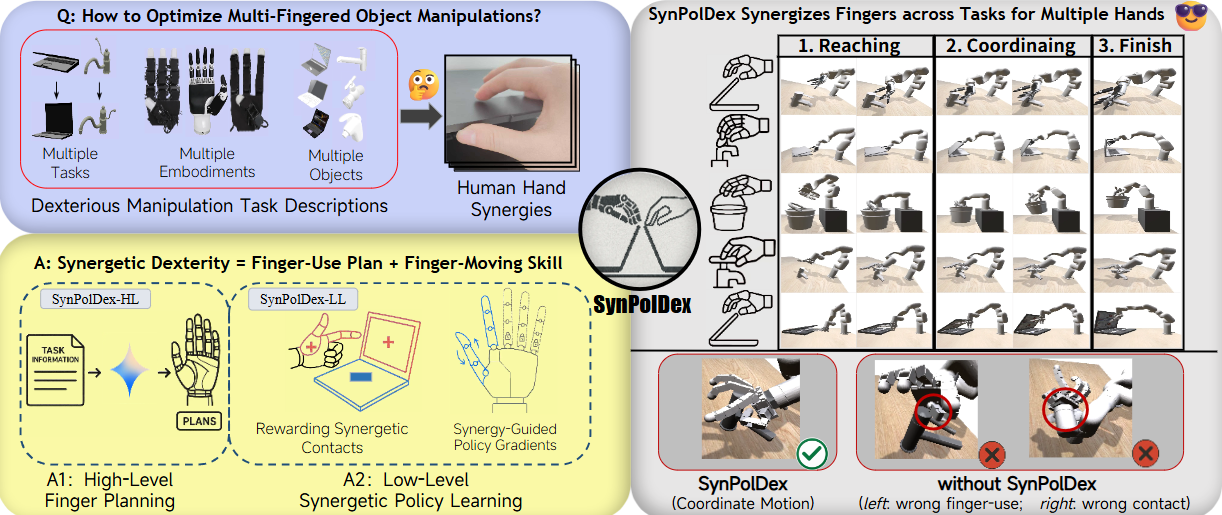
SynPolDex — Synergizing Fingers via Bi-Level Policy Learning
A bi-level framework for finger coordination in multi-fingered robot hands, combining high-level finger-role planning with low-level control.
SynPolDex starts from a stricter question than generic dexterous RL: which fingers should lead, which fingers should support, and how should that assignment change across tasks, objects, and robot hands?
The core idea is to split dexterity into two levels: a finger-use plan at the top, and a synergy-guided control policy at the bottom.
Problem framing
Multi-finger manipulation often fails for two different reasons. First, the same task demands different coordination patterns under different hand embodiments: Allegro, Inspire, and Leap do not share the same kinematics or thumb geometry. Second, standard end-to-end RL tends to smear credit over every joint, even when only a subset of fingers should dominate the action.
SynPolDex responds by making finger roles explicit. The method asks the policy to decide not only how to move, but also how the fingers should divide labor.
Bi-level policy
At the high level, a vision-language model reads the task scene and produces a finger-use plan:
where denotes visual task cues, is task information, and summarizes hand-specific or synergy-related priors. The output plan specifies which fingers should lead, stabilize, or stay secondary.
At the low level, the controller conditions on that plan:
A compact way to summarize the low-level mechanism is:
so reward reshaping and advantage assignment concentrate gradient on the fingers that matter for the chosen role allocation. This is the clean part of the design: the high level tells the policy which fingers should be important, and the low level changes credit assignment accordingly.
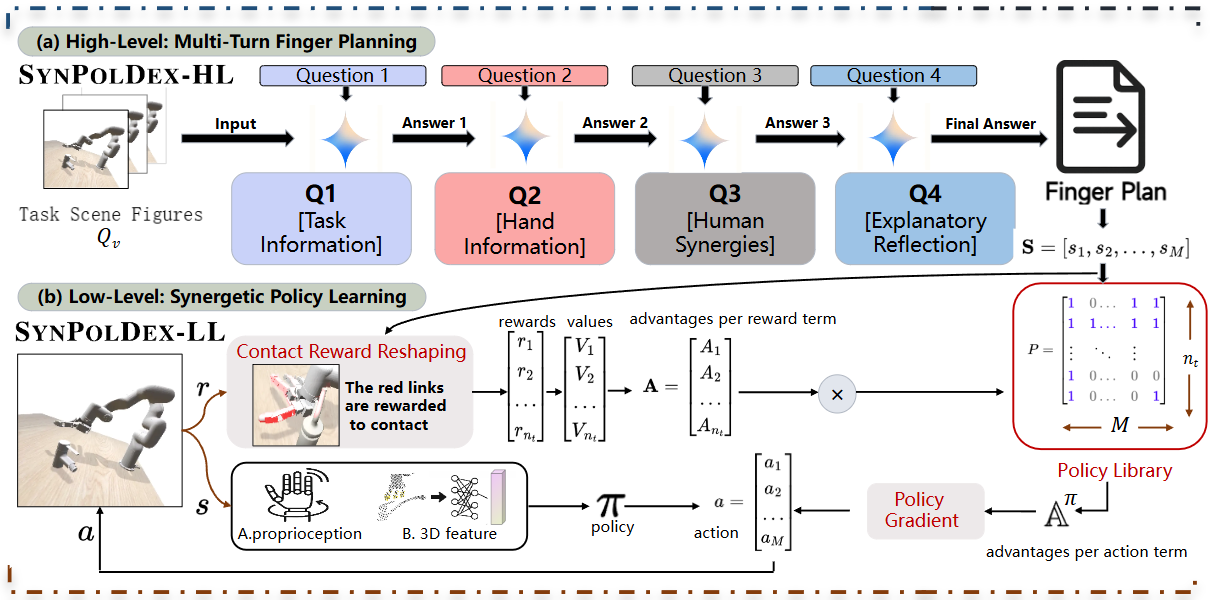
The pipeline is explicitly split into multi-turn finger planning and synergy-guided low-level policy learning.
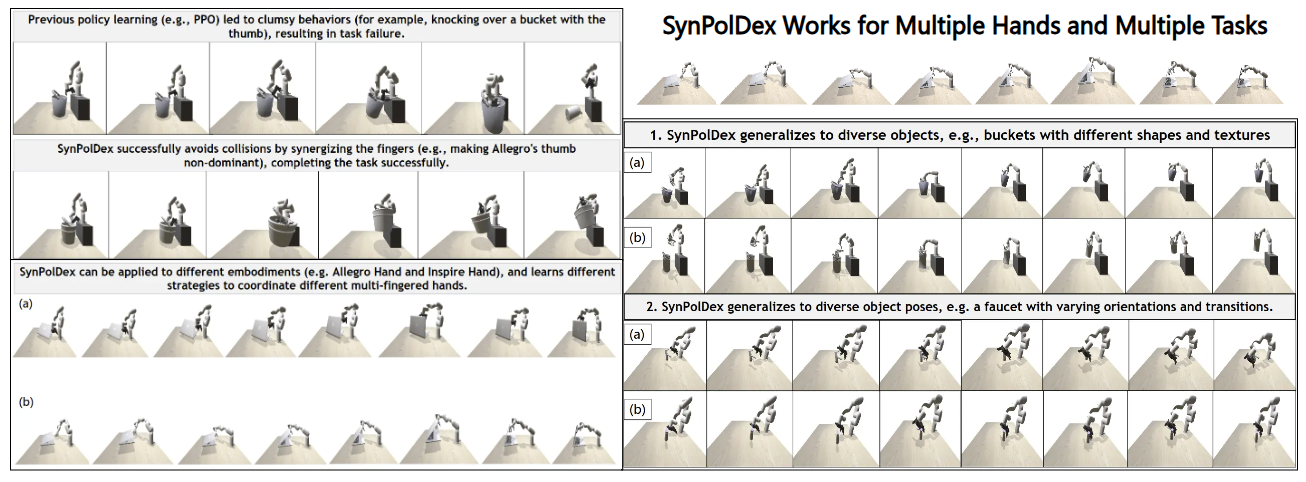
The same principle transfers across containers, faucets, buckets, and bottles rather than only a single benchmark object.
Why the decomposition helps
This bi-level split is useful for three separate reasons:
- it gives a typed interface between language-level planning and continuous control;
- it improves credit assignment by avoiding all-fingers-are-equal updates;
- it makes cross-embodiment generalization easier, because the plan can adapt before the controller does.
In other words, SynPolDex is not only a stronger policy. It is a cleaner way to say where symbolic structure ends and where motor learning begins.
Results and generalization
Evaluated on the DexArt-m benchmark across four manipulation tasks:
| Task | Hand | Success Rate |
|---|---|---|
| Toilet lid | Allegro | 90% |
| Faucet | Allegro | 82% |
| Faucet | Leap | 76% |
| Laptop lid | Allegro | 58% |
| Bucket | Allegro | 56% |
| Toilet lid | Inspire | 52% |
The broader result from the paper is that SynPolDex outperforms the PPO baseline by 26% in task success and by 2.6x in human-likeness evaluation. That second number matters: the method is not only completing tasks more often, but doing so with finger usage that is easier to interpret.

The result panel highlights two kinds of generalization: new object shapes and new poses within the same task family.
Takeaway
The paper makes a narrow but important claim: dexterous manipulation improves when finger roles are treated as explicit latent structure rather than hidden side effects of PPO. That claim is modest enough to test, strong enough to transfer across hands, and concrete enough to be useful in future embodied-agent systems.
Venue
Published at 2025 IEEE-RAS 24th International Conference on Humanoid Robots (Humanoids).
Authors: Yanming Shao, Yan Ding*, Chenxi Xiao*